By: Atish Kathpal
Published: 17 Jan 2023
Last Updated: 17 Jan 2023
KnowBe4's SecurityCoach is a cybersecurity awareness SaaS product which integrates with 50+ leading security products such as Crowdstrike, Zscaler, Netskope and others. SecurityCoach can scale to ingest 10's of millions of security events everyday, analyzing them in real time and pushing micro-learning modules to educate and inform the user in direct response to their risky behavior. At the core of this product is a multi-stage data pipeline that ingests, transforms and enriches the incoming events to derive insights, identify risky behavior and trigger real time responses, thus helping our customers manage the human layer of cybersecurity.
In this blog, we discuss the high level architecture of our data processing pipeline as well as our recent experience extending the pipeline in response to evolving needs of the product using orchestration capabilities of AWS Step Functions.
In our experience, data processing pipelines tend to get complex over time as pipeline load increases, more infrastructure components get added and product requirements evolve. At a high level, a typical data pipeline is comprised of multiple stages such as ingestion of data from various sources, processing and applying multiple transformations on incoming data, storage of data into data stores, triggering responses at the end of the data pipeline.
The existence of multiple steps results in the need for orchestration to automate processes like move data between different stages, monitor the flow of data, ease of plugging in more transformation steps in the data pipeline, error handling, alerts etc.
Our data pipeline (evolved over the last couple of years) is architected on the core principles of being event driven, serverless and designed for streaming/real time event processing. This allows for analytics, reporting and responses in real time. It leverages different AWS services such as:
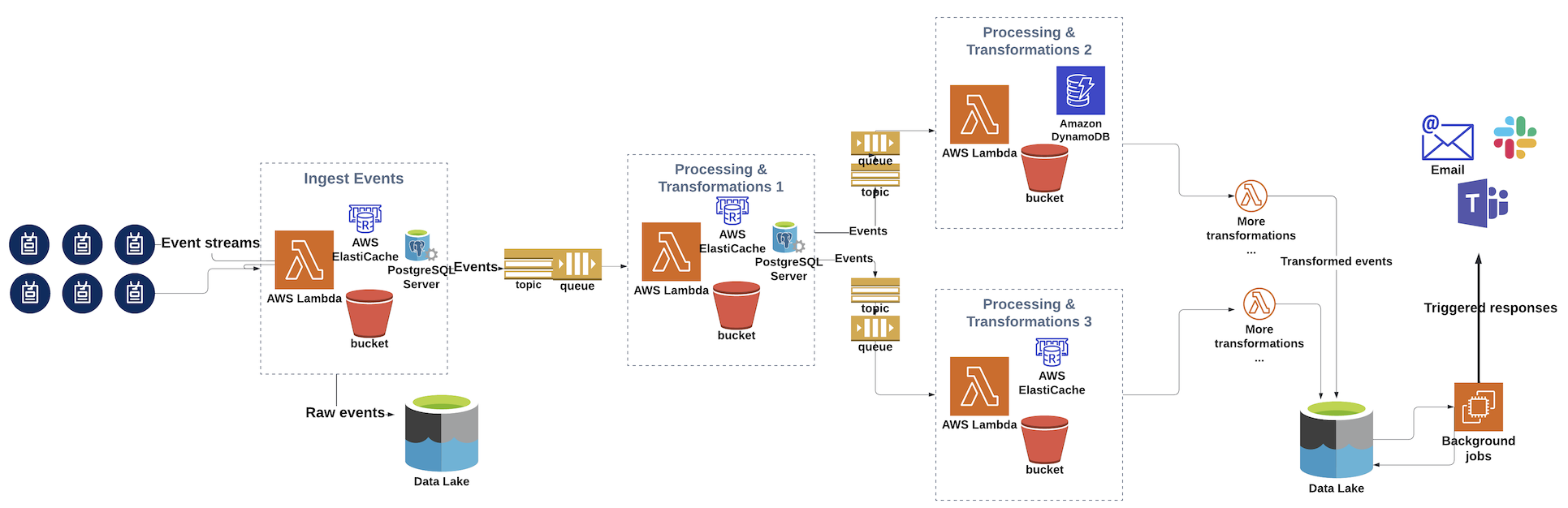
Recently, we were looking to add some additional stages to the data pipeline based on new product requirements. The new stages would activate for a subset of events based on customer provided rules. These rules could vary in complexity, business logic and outcomes. One approach to address such requirements would be to add more lambdas for additional event processing, along with persistence, caching of useful metadata, rules and SNS/SQS based plumbing to trigger downstream lambdas. The logic of which subsequent lambdas to trigger depending on different criteria could be codified in the existing and new lambdas themselves.
We realized this would soon become complex and our site reliability team would also frown at the thought of having more queues, lambdas, containers to monitor and scale. It would also be a challenge to respond to any bottlenecks in production environments without a blueprint of architecture and an understanding of the flow of events through the pipeline, given the flow was codified into each lambda.
The team wanted to reduce the overhead of conditional event routing and plumbing of services to add more steps to the pipeline. We started exploring orchestration services which could help manage our data pipeline, with the intent that we could focus our energies more on the business logic.
To tackle the evolving needs of the product now and in future, as well as for better infrastructure management, it is beneficial to leverage orchestration services for data pipelines.
We chalked out our high-level needs of orchestration as follows:
While some of these needs were already met with our existing design, the idea was to identify services that can meet all of these requirements to help minimize our engineering effort as our pipeline evolves. After exploring a few options, we zeroed upon AWS StepFunctions. In the following section we talk more about this service, it’s limitations, advantages, from our lens of running a real time data processing pipelines.
AWS Step Functions (SFN) worked for us on multiple fronts. The native integrations with AWS Lambda and a host of other AWS services, ability to handle failures and retries, event driven way of invoking the Step Functions and ability to monitor and visualize the workflows were big wins. Moreover SFN supports multiple ways to invoke as listed here. One can hence easily plug-in Step Functions into their existing pipelines to orchestrate the new stages of the pipeline without having to migrate the complete pipeline.
Besides AWS Step Functions, we also evaluated Amazon Managed Workflows for Apache Airflow (MWAA). Airflow is open source and a popular orchestration platform which helps model workflows as Direct Acyclic Graphs (DAGs). However, in our evaluation we found it better suited for long running batch processing data pipelines rather than for our use case of real time processing. ### Creating a Step Function
Creating a Step Function is as simple as drag/drop of required AWS services using the Workflow Studio.
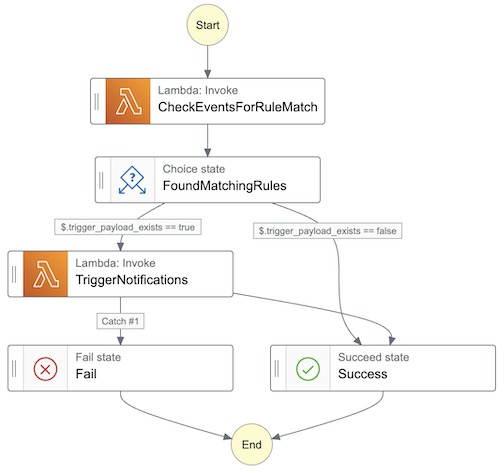
It automatically builds the state machine definition, in Amazon States Language. One can configure retries on failures in the state machine definition itself.
{
"Comment": "Sample state machine to demonstrate AWS Step Functions",
"StartAt": "CheckEventsForRuleMatch",
"States": {
"CheckEventsForRuleMatch": {
"Type": "Task",
"Resource": "arn:aws:lambda:CheckEventsForRuleMatch-Lambda",
"Parameters": { "Payload.$": "$" },
"Retry": [
{
"ErrorEquals": ["Lambda.ServiceException", "Lambda.AWSLambdaException", "Lambda.SdkClientException"],
"IntervalSeconds": 2, "MaxAttempts": 6, "BackoffRate": 2
}
],
"Next": "FoundMatchingRules"
},
"FoundMatchingRules": {
"Type": "Choice",
"Choices": [
{ "Variable": "$.trigger_payload_exists", "BooleanEquals": true, "Next": "TriggerNotifications" },
{ "Variable": "$.trigger_payload_exists", "BooleanEquals": false, "Next": "Success" }
]
},
"TriggerNotifications": {
"Type": "Task",
"Resource": "arn:aws:lambda:TriggerNotifications-Lambda",
"Parameters": { "Payload.$": "$" },
"Retry": [
{
"ErrorEquals": ["Lambda.ServiceException", "Lambda.AWSLambdaException", "Lambda.SdkClientException", "AllNotificationsFailedException"],
"IntervalSeconds": 2, "MaxAttempts": 6, "BackoffRate": 2
}
],
"Catch": [ { "ErrorEquals": ["AllNotificationsFailedException", "UnknownException"], "Next": "Fail" } ],
"Next": "Success"
},
"Fail": { "Type": "Fail" },
"Success": { "Type": "Succeed" }
}
}In our evaluations, the orchestration overheads were minimal. For a simple 3 step state machine, where 1 second was spent on each stage, we saw an overhead of only 100ms to 900ms with hundreds of workflows running in parallel. We noticed that the minuscule execution overhead is due to occasional cold start of lambdas themselves rather than the orchestration overhead of using Step Functions.
One can use Localstack for testing locally using step functions with no AWS footprint at all. All one needs to do is dockerize the apps. Optionally, AWS also provides a Step Functions local runner for testing.
# Lambdas
aws --endpoint-url=http://localstack:4566 lambda create-function --handler lambdas.check_rules.handler --runtime python3.10 --package-type Image --timeout 900 --function-name check_rules --code ImageUri=build-lambda-services:latest --role arn:aws:iam::000000000:role/lambda-ex --environment "{}"
aws --endpoint-url=http://localstack:4566 lambda create-function --handler lambdas.trigger_notification.handler --runtime python3.10 --package-type Image --timeout 900 --function-name trigger_notification --code ImageUri=build-lambda-services:latest --role arn:aws:iam::000000000:role/lambda-ex --environment "{}"
# Create role
aws --endpoint-url=http://localstack:4566 iam create-role --role-name Test --assume-role-policy-document '{\"Version\": \"2012-10-17\", \"Statement\": [{\"Effect\": \"Allow\", \"Principal\": {\"Service\": \"states.amazonaws.com\"}, \"Action\": \"sts:AssumeRole\"} ] }'
# Create step function state machine
aws --endpoint-url=http://localstack:4566 stepfunctions create-state-machine --name example-step-function --role-arn "arn:aws:iam::000000000000:role/Test" --definition file:///docker-entrypoint/example_step_function_definition.json The payload size that can be passed between steps is capped at 256 KB. To work around this limitation we chunk the incoming data prior to invoking the SFN such that the event payload remains within limits. One can have upstream lambdas transform events to a common structure, thus limiting the fields in each event to only those relevant for us. This also helps cap the per event payload and we can arrive at the right batch size to remain within Step Function payload limits.
Another aspect to consider is that Step Functions do not have an in-built scheduler. This can be worked around leveraging Amazon CloudWatch events to invoke the workflow.
Another aspect to be cognizant of is 15 mins AWS Lambda execution limit when designing a serverless workflow. Moreover, one should also choose the right kind of Step Functions - Standard or Express, when designing the state machine as they come with their own limits and quotas. In our case, we went with Standard Workflows as our state machine completes within 5 minutes and it also provides better visualization and exactly once execution support.
Do you want to join us to address these challenges? Have something to contribute? Passionate about purpose-driven, highly-productive software development? Send us your resume! KnowBe4 Engineering is always looking for more talented engineers just like you! Check our open positions on our careers page - www.knowbe4.com/careers.


KnowBe4 Engineering heavily uses On-Demand environments for quick iterations on native cloud-based…

How KnowBe4 solved the "It Works on My Machine" problem with a new approach to provisioning test…