By: Zane Garner
Published: 23 Jan 2023
Last Updated: 23 Jan 2023
In today’s modern and dynamic software development landscape, test automation has become a standard across the majority of R&D teams. Though its implementation may look different from organization to organization, the driving factors for its needs are mostly the same:
As software development teams shift to continuous deployments, changesets are deployed at a much quicker cadence. We no longer have the ability to sit back and wait for changesets to flow through a traditional and often slow release cycle such as: Staging,QA, and Prod environments. As Engineers are constantly adding new features, implementing refactors, and fixing bugs, APIs and UIs are bound to change. Having the ability to account for these changes, simulate a user’s workflow and interaction with your product, while having it run on a consistent basis to ensure your product hasn't regressed sounds great in theory, but let's take a look at some real world limitations and bottle-necks of this idea:
Prod is oftentimes limited by the amount of access you have to required microservices as well as the degree and state of public APIs. This results in tests that only work in Staging or QA but can't run on Prod due to permissions, certain service limitations, etc.When we started our journey into Test Automation, we wanted to empower QA to write automation, so we implemented a flagship automation tool. This tool had all the bells and whistles; reporting, world-class object identification, ability to write code directly not just record & playback. However, we soon ran into multiple instances of the aforementioned limitations listed above. The tools were rigid, they weren't "built for us", we didn't have a centralized reporting system, we couldn't run it at scale, and nowhere near the levels of concurrency we needed. So, we made the switch and started to build our own custom-rolled automation framework to handle all facets of test automation we needed; UI Testing, API Testing, Integration Testing, and Simulated Load Testing.
Our UI Testing framework is built on the open-source Selenium Project which is a widely adopted standard. But recalling the UIs are inherently flaky pain point, we decided to build out our own Page Model generator, and it was worth the effort. Gone are the days of not knowing when an object has changed on a webpage. At runtime we can identify if a Page Model has changed and flag the test for review with page specific metadata. This generator builds out our class files which we leverage at runtime in our test harness to access elements by page.
The next step was solving environmental differences. The question was; how do we build Page Models that are designed for Prod while accommodating for variations in potentially hundreds of other On-Demand environments? The answer was git-flows. We leveraged different branching strategies to split out our Tests projects and their artifacts from the business logic. We paired environments to branches and leveraged a custom integration with Jira to identify what environment a test can run on.
To overcome the UI Testing is often slow... pain point, we designed a highly scalable serverless automation stack in AWS. The framework scales rapidly to as many tests as we want to run concurrently which we heavily leverage in our day-to-day engineering practices. It consists of a suite of step functions, lambdas, fargate containers, and SQS queues that handle the orchestration of launching thousands of test suites at once and provides rapid feedback to changesets deployed to any of our environments.
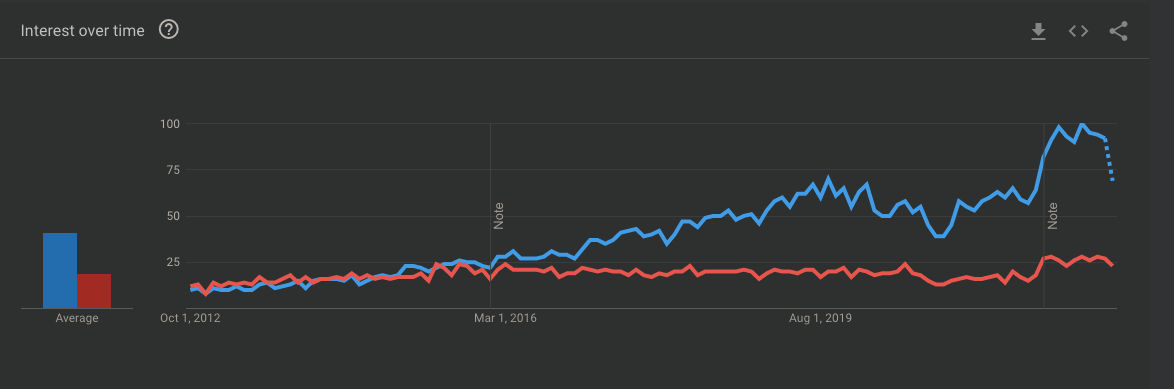
API Testing is great. It's continued to take dominance over UI Testing as shown by this Google trends result over the last 10 years.
For API Testing we designed a business-driven-development framework that empowered Project Managers, Software Engineers, and Quality Assurance Engineers to create test scenarios leveraging the Gherkins Syntax (Given, When, Then). By enabling other members of the SDLC process to contribute to these tests, we saw a large increase in the adoption rate of API Testing as a standard in all of our projects.
Today, Engineers are able to make changes to backend systems and run a full suite of API tests locally in minutes. Our Engineers contribute to our tests and take ownership over their test quality, agility, and performance as a whole.
For Load-Testing, we considered some very important questions; How do we know if the platform is scaling as expected? Are our microservices experiencing performance degradation? How can we be sure new features can handle the level of traffic we expect and then some?
By implementing our UI testing framework with an emphasis on horizontal scaling, we were able to leverage it as a basis for our simulated load-testing efforts. Firstly, we created integration tests that tested end-to-end workflows between our microservices. These tests provided the foundation for our load-testing as well as valuable baselines. Secondly, we were able to sit down with the stakeholders and discussed the business requirements, expected load, maximum thresholds, and obtained all acceptance criteria. From this, we began the process of running simulated load against the platform and features. We started with a controlled set of inputs and we started to turn up the knob, little by little. At each step, we gathered metrics on network performance, UI render times, and DB loads. From here we started painting a picture of how the platform responded to this test scenario. We do this to all new features that require this level of testing which is assessed by the project teams.
Have something to contribute? Passionate about purpose-driven, highly-productive software development? Send us an application! KnowBe4 Engineering is always looking for more talented engineers just like you! Check our open positions on our jobs page - www.knowbe4.com/careers.


KnowBe4 Engineering heavily uses On-Demand environments for quick iterations on native cloud-based…

How KnowBe4 solved the "It Works on My Machine" problem with a new approach to provisioning test…